
TL;DR: We’re taking a look at Outfit7’s art pipeline and how we transitioned from a proprietary system to the commercial solution — and a de facto industry standard — ShotGrid.
Hi! My name is Samy Ben Rabah and I’m a software engineer at Outfit7, working on the art pipeline between my coffee breaks. What’s an art pipeline? Read on to find out!
What do you mean by “pipeline”?
Have you heard of the fun little cat who repeats absolutely everything you say and bugs you when he’s hungry? Did I hear “My Talking Tom”? Right you are! You’ve won two points!
But how did this cheeky little feline manage to sneak into your smartphone? Was it through a backdoor or a cat flap? Nope. The answer is that Tom has literally been “pipelined” into your phone!
At Outfit7, we produce many games, including My Talking Tom and My Talking Angela. Each one is made up of many different elements, such as 3D characters, props, environments, animations, sounds, UI elements (backgrounds, buttons, and app icons), as well as promo material, ad banners and more to support the game’s promotion and distribution.
Game developers implement the game logic and other mysterious bits and pieces, then everything gets packaged into an app that you install on your phone — et voilà!
These elements are created by artists from different departments who intervene and contribute at different stages of the production. They use a collection of software (Autodesk Maya, Adobe Photoshop, SideFX Houdini, Adobe Substance Painter, etc.) to create assets, which are finally exported in a form that’s suitable for the game engine. Assets might be, for example, animations in Maya exported to .fbx, or multilanguage localisations exported to .png from a Photoshop file.
To support these processes through the different stages of production, a management system is required, which we simply call the “pipeline.”
Why do we need a “pipeline”?
Let’s look at a practical example to see why a “pipeline” is indispensable:
Let’s say an animator is assigned an animation to work on.

Typically, the animator would reference one or more external rigs (e.g. character, props) in Maya and animate them using diverse techniques (e.g. inverse kinematic, blend shapes, possibly some dynamics)
Because the Maya animation is a working file, it cannot be directly used in the game. Therefore, it must be processed and exported in a form that’s suitable for the game engine:
Rig joints need to be baked.
The rig needs to be stripped of unnecessary nodes, some nodes might be renamed, etc.
The baked animation is then exported to .fbx in a specific location with a specific naming convention. If we have multiple rigs, they’re each exported separately using specific naming conventions.
And so on…
Obviously, these operations would be done by an exporter script that the animator would run and voilà, we have our animation in the game engine! Beautifully simple, isn’t it?
But, before we can reach this export stage, we need to take some aspirin and ask ourselves a few simple questions:
1. How do we organise and keep track of our animations (and all the other assets)? Do we use a big colourful spreadsheet to organize these tasks by category/task name?
2. How does the animator “publish” a new version? Does she work locally and then copy the file in a predetermined network location using an agreed naming convention?
3. If, by accident, two animators work on the same file, how would the conflict be resolved — or prevented in the first place?
4. The animation might use one or more rig Maya files. How does the animator know where to find these? How does the animator update the rigs? Does she browse the file system and search for updates? How does she know when updates are available?
5. All the referenced files (rigs, textures, etc.) would normally be copied locally instead of being directly referenced from the network. How does the artist know what files this Maya scene depends on?
6. If we would like to have these files on the cloud, how would artists fetch them and how would they upload their published files?
7. How does the animator know where export scripts are located? Would she copy them locally? How would she get updates?
8. If the animation exporter has settings specific to a project, how can we make sure the animator uses the proper settings? Do we provide a different exporter for each project with hardcoded settings? Or are they set manually?
9. How can we track what the animator is working on? How can we schedule the tasks she’s working on? Should we use a spreadsheet?
And on and on ad infinitum. Do you have a headache yet? If not, you should!
Without a system taking charge of all these processes, and relying on people manually taking care of all the details above (and many more), it’s safe to say we’re doomed.
And this is where our pipeline comes into play…
Here’s what the pipeline can do for us:
Project management, organization of assets: The pipeline helps to organize projects and assets in a logical structure. Systematic organization allows for predictable asset location and naming conventions
Asset centralization: Assets are published, versioned and stored on the network or remote storage, ensuring they’re backed up and accessible when needed.
Metadata publishing:The pipeline stores metadata associated with published content, such as the creator, description, file size, etc.
Dependencies: The pipeline keeps track of dependencies. In the example above, a published Maya animation file would have information about the rigs it references and each published rig would have links to textures it references, and so on. If you were to pull this Maya file up on your machine, it would be possible to recursively go through all the dependencies and collate all the files required to get a functional scene.
Integrations, toolsets, unified workflows: Typically, a pipeline will have integrations in various applications, such as Photoshop, Houdini and/or Maya and will have an API/toolkit allowing you to customise or write new integrations. A dedicated UI would allow the user to navigate through the assets without having to know where the actual files reside on the network or cloud. This also makes it easier to get a unified set of tools, such as exporters. This allows for the unification of workflows, resulting in reproducible outputs.
User management: The pipeline helps to manage users, and assign them to projects and tasks. It also allows you to assign permissions with various levels of granularity. For example, you can restrict users to specific projects.
Project management, planning, tracking:
Artists are assigned tasks, which can be scheduled in a global plan. For instance, before it can be animated, a character needs to go through a concept/model/rigging phase. Such tasks can be planned chronologically in a Gantt chart.
Without a pipeline, trivial operations, such as naming files and saving them in the correct location, would have to be done manually, inevitably leading to errors and making the whole production extremely painful.
Outfit7 art pipeline
The Outfit7 art pipeline is currently undergoing a transition from a proprietary system to ShotGrid, a commercial solution and de facto industry standard.
Juggernaut: the old way
Our in-house pipeline, which we call “Juggernaut” (actually the frontend UI) was developed over several years. We could say that it was developed “organically” with some planning and design here and there. But in reality it was much more like a hot potato…
Juggernaut revolves around the following components:
a backend powered by Django and a MySQL database
a file server mounted on artists’ machines
a Python/PySide2 frontend (Juggernaut) used by artists to publish their work
a collection of exporters (Photoshop, Maya, etc.)
a web UI for project creation and user assignment
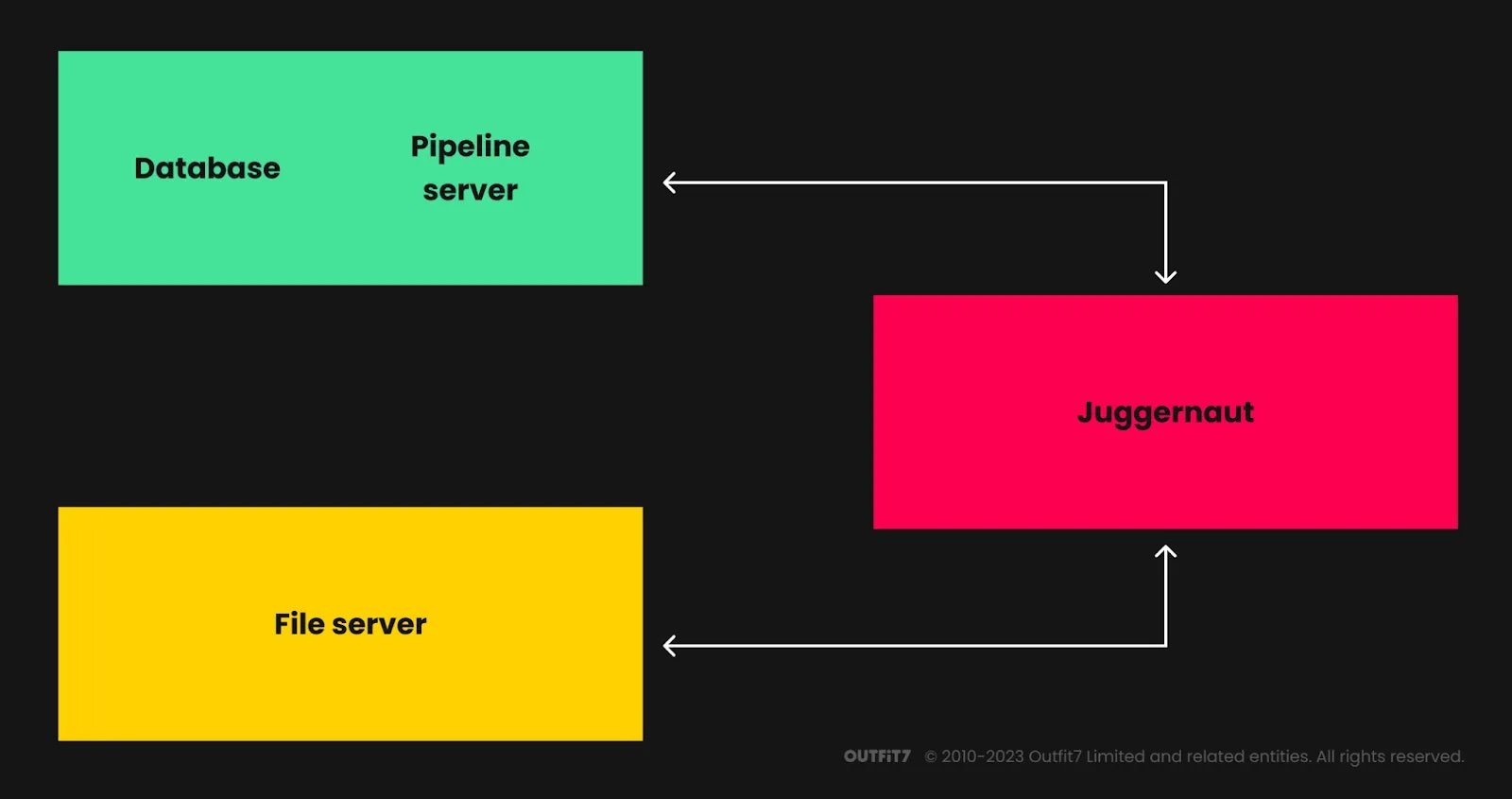
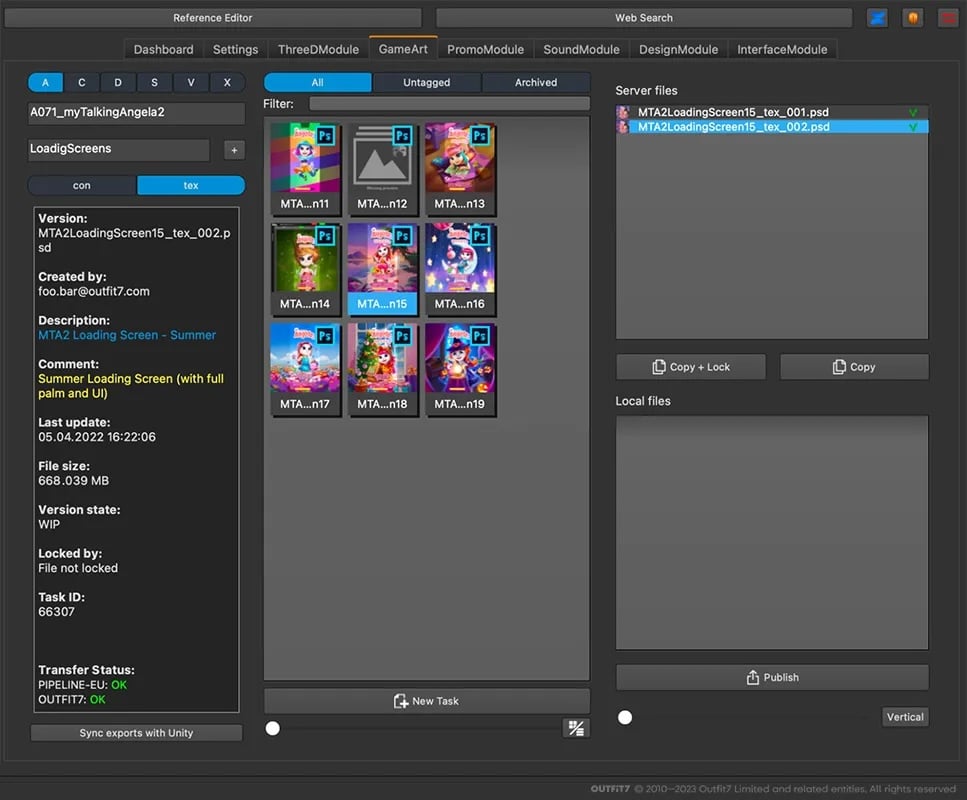
In a nutshell, Juggernaut works as follows: Each project is organised into Project/Modules/Categories/Tasks/FileVersions. Artists work on tasks (UI elements in Photoshop, 3D models, rigs, Maya animations, Substance Painter textures, etc.). These artists work locally and publish versioned files, which are copied to the server. Then, they export various files using custom exporters:
game exports (to Unity or Starlite, our proprietary game engine) such as app icons, geometry/rigs/animations to .fbx, etc.
promo materials for campaigns, ad banners, thumbnails, etc.
File system
In our in-house pipeline, everyone had write access to the file server, resulting in a lot of “dark matter” accumulating over the years: gigabytes of data whose mysterious presence could be felt, without anyone being able to tell what it was used for. To make things worse, there were also cases of users editing published files directly or accidentally overwriting them — or even worse, corrupting the file and making it unreadable.
The external pipeline
Initially, Juggernaut was designed to work only from within our intranet. This required a VPN connection in order to access it from outside. It also required a lot of maintenance, and also posed a potential security risk when giving access to external artists. Moreover, the performance was really poor because files were accessed over Samba.
A system called the “external pipeline” was then developed to allow external users to use Juggernaut via an external site with database replication and using a local server. The development of this system was accelerated when everyone started to work remotely during the Covid-19 pandemic.
Over the years, Juggernaut has served its purpose. It’s been used for many games, despite its limitations and bugs. A lot of our time was spent fixing bugs and supporting users instead of focusing on new features.
Additionally, this pipeline only tracked published file information, but it lacked tools to support project management, task tracking and reviewing.
So, in mid-2021 we decided to abandon Juggernaut and adopt ShotGrid for our pipeline.
ShotGrid: the new way
Autodesk ShotGrid (formerly known as Shotgun) is a production management system with integrations with most standard digital content creation (DCC) software and extensive APIs. Its main features and advantages are:
production tracking, task planning, Gantt, reviewing
user management, high granularity permissions system
it’s highly customisable, thanks to its Python/REST APIS and Shotgrid Toolkit and customisable schema
customisable web pages and views
advanced search and filtering
extensive developer documentation/samples/git repos/community/forums
industry standard: it makes it easy to enrol new users
good customer support
We began development on Shotgrid in mid-2021, and the transition required the following developments:
Pipeline development:
adapting the base pipeline configuration as well project structure to meet our needs
writing new frameworks/apps and custom hooks (see “hooks” section)
refactoring exporters
Unity integration to access ShotGrid
developing a client UI to download published files from AWS S3 bucket
writing Event Daemon scripts (triggered upon ShotGrid events)
migrating our existing projects to ShotGrid
Production:
leveraging ShotGrid’s powerful production management capabilities such as task assignment, tracking, review system, custom pages.
onboarding users to ShotGrid and changing workflows
migrate previous tools (Trello, spreadsheets) to ShotGrid pages
Pipeline development
Custom entities
ShotGrid is quite flexible and lets you update the database schema by creating custom entities, as well as adding and editing fields of different types (text, float, int, boolean, entity fields etc.) We used these to create new entities, such as Categories or ApplicationSettings (holding config JSON data) and also added fields to existing entities.
ShotGrid Configuration
We started with the default toolkit pipeline configuration and adapted it to fit our needs using the ShotGrid APIs: The ShotGrid Python API and rest API was used to interact with the ShotGrid database to create/update/delete/edit entities. The Shotgrid toolkit API was used for DCC app integrations.
We learned all about the inner workings of ShotGrid (and some of its limitations) while developing new features.
Files on the cloud
Early on, we determined that we wanted to have our files on the cloud. Although the ShotGrid toolkit doesn’t have a built-in mechanism to deal with cloud-based files, it does allow you to write frameworks and hooks to achieve it. We developed a remote storage framework to handle file transfer to our Amazon S3 bucket for exactly this purpose.
Custom hooks
The ShotGrid toolkit has a nice feature where the apps, engine or framework can be extended via hooks, which are Python functions that override and extend the base class behaviour.
Each app has a YAML configuration file, where you can specify an inheritance chain for a specific engine and context, and define where the Python code will reside.
For instance, the publish collector (which is the phase where the files that need to be published are collected) was extended to meet our specific needs, and are engine-specific.
settings.tk-multi-publish2.maya.asset_step:
collector: "{self}/collector.py:{engine}/tk-multi-publish2/basic/collector.py:{config}/tk-maya/tk-multi-publish2/basic/collector.py"
# the {config}/tk-maya/tk-multi-publish2/basic/collector.py part adds Maya
# specific code for the maya publish collectorFor example, you can:
collect linked smart objects in Photoshop files
collect textures, rig exports, 3D geometry
collect animation .fbx exports and playblasts
Pre-publish validation
Another example of a hook is the validation stage. This is an opportunity to run some checks before allowing the publishing to go through, preventing problems down the line and resulting in cleaner published data. This was a major improvement in comparison to our in-house pipeline.
For example, you can:
check if the user added a comment/thumbnail to the published file
check if there’s enough disk space to accommodate the new publishes and exports
check if a referenced Maya file/texture/linked smart object is under the project root
check if a rig conforms to the expected structure and naming convention
plus many more possibilities!
Publish finalize
Another example of hook is the publish finalize, which is invoked after the publish is completed. Since our files are stored on Amazon, this is where the actual upload of the published files starts.
Event Daemons
ShotGrid has an event stream where nearly every operation on the ShotGrid database is recorded. It’s therefore possible via an Event Daemon or a web hook to execute some operations upon certain events. We deployed an Event Daemon (running on some container somewhere in cyberspace) and are adding scripts, such as:
sending an alert when a duplicate category or asset is created
sending a Slack notification when someone leaves a note on your version
and more
Apps
The ShotGrid toolkit allows you to create new apps that can be started from the ShotGrid Desktop and which communicate with ShotGrid. For example, a disk space management app was created for artists to safely clean up their published files (especially problematic Photoshop files under 1.5GB).
Another app (currently in the making) is a Maya batch exporter allowing you to send Maya batch exports on a remote machine from a published Maya scene.
Frameworks
As mentioned earlier, we wrote custom frameworks, which are libraries that can be reused in apps and engines.
Among others, we created:
a remote storage framework to handle the file transfers to an Amazon S3 bucket
an ExtendScript-library framework containing our ExtendScript libraries and exporters for Photoshop, as well as binaries such as ImageMagick
a common library framework with common code such as ShotGrid API utilities.
a Maya framework with Maya-specific functions as well as shelves, plug-ins, etc.
Maya plug-ins, scripts and shelves are bundled in the Maya framework and all the setup (such as Maya script/plugin/module paths environment variables, directory remapping, default units, etc) is done “under the hood” when users launch Maya from the ShotGrid desktop. Without such a system, artists would have to set up everything manually, which would involve needing pipeline developers to assist them at some point. It would also result in discrepancies in artists’ setups and it would also be difficult to push updates.
Deployment
The ShotGrid toolkit defines the project setup, such as file system locations and templates, as well as frameworks/apps/engines and their versions in a pipeline configuration. We deploy our frameworks in beta configurations that artists can test before updating the master configuration. This is really quite an improvement compared to what we used to have with our in-house pipeline and Juggernaut.
As far as the deployment is concerned, we made our lives easier by writing config management tools to easily upload updated frameworks and generate new configurations and propagate them to all the projects (we currently have nearly 100 projects at the time of writing…)
Old project migration
We migrated a lot of old projects from our old pipeline to ShotGrid and, given the scope of the task, it had to be automated. For this purpose, we developed a migration tool using the ShotGrid Python API.
The process consisted of the following steps:
scanning the Juggernaut project to generate a big data structure containing all the publish metadata: categories/tasks/file versions, application settings
mapping the old file versions to their ShotGrid PublishedFile equivalents and populating the destination ShotGrid project (categories, assets, tasks, PublishedFiles, versions, thumbnails, etc.)
recording PublishedFile upstream dependencies
migrating application settings (stored as JSON data) to their ShotGrid equivalents (using custom entities).
uploading the files to our AWS S3 bucket.
Maya files and references
The biggest challenge was dealing with Maya files containing references to external files (such as other Maya files, textures or audio files), which then had to be remapped to match the ShotGrid paths.
Given the number of files, it was unrealistic (if not impossible) to run Maya batch processes to substitute these paths. Fortunately, all our Maya files were in the ASCII format, and a simple text substitution was done (thank you, regular expressions!), which worked well.
Additionally, upstream dependencies were also recorded. These dependencies are, for example, other Maya scenes or textures that a Maya scene depends on. This information is crucial in order to download a fully functional Maya scene.
The final step was to upload the new published files to an AWS S3 bucket.
We had around 25 projects to migrate and each was spun off into a game and various distribution projects. This resulted in a total of around 50 ShotGrid projects. An initial pass was done to migrate the bulk of the projects (while we were still using the old pipeline) and, later on, incremental migrations were done for the final switch.
Here are some numbers to illustrate the scope of the migration:
~ 50 projects
~ 29k assets
~ 290k migrated files
~ 14TB of data
Some artists tested and validated the migrated data on samples and also carried out test exports to confirm the migration was backward compatible and producing the expected outputs.
Conclusion
According to experts, the wheel was invented a few thousand years ago. So why reinvent it? Why not use an established and proven system and focus on the important bits instead?
Although our old pipeline helped us produce many games, it lacked flexibility, had limitations and it used a good chunk of our resources to duct tape over issues and fix bugs instead of spending our time developing new features.
In this context, the switch to ShotGrid made sense. Thanks to its solid foundations and flexibility, it’s definitely a plus for our pipeline and for the production of our future games.
The switch to ShotGrid took longer than expected, but the advantage is that we had time to consolidate the codebase. Moreover, our artists are now more familiar with ShotGrid and the new workflows. They’re progressively getting rid of their ingrained habits, built over years on our old pipeline.
We’re now in the process of shutting down our old pipeline and fully switching over to ShotGrid. So, RIP Juggernaut. Welcome, ShotGrid!


